
以外にも早く AI が身近なところで
使われてきたね!
AIに仕事を奪われる日も
そう遠くはなさそう・・・
今からでも遅くないよ!
まずは「機械学習」から少しづつ学んで
AI技術に対応できるスキルを身につけよう!
AI(人工知能)は、私たちの生活に深く浸透し、その応用範囲はますます広がっています。
その中でも、機械学習はAIの基礎的な技術の1つであり、大量のデータからパターンを学習することで、自己判断や予測ができるようになります。
「よし!機械学習を理解してAI技術に対応できるスキルを身につけるぞ!」と考えているあなた!
初心者にとっては機械学習の専門用語やアルゴリズムが難しく、学習のハードルが高いことも事実です。
AIに関する情報はどれも、「キーワードを知っている前提で書かれていることがほとんど・・・」ではありませんか?
そこで本記事では、機械学習に欠かせないキーワードを、初心者にもわかるように解説しています。
ぜひ、AIに興味がある方は参考にしてください。
機械学習でよく使われるキーワード:難易度順
以下に、機械学習でよく使われるキーワードを、難易度順に一覧で表示します。
- クラス分類
- 回帰
- 教師あり学習
- 教師なし学習
- 強化学習
- 深層学習
- ニューラルネットワーク
- バッチ学習
- オンライン学習
- ディープラーニング
- ランダムフォレスト
- SVM
- PCA
- k-NN
- モデル選択
- クラスタリング
- 次元削減
- 特徴選択
- 正則化
上記の一覧表には、機械学習でよく使われるキーワードが並んでいます。
これらは難易度順に表示されており、初心者にとっては見たことがあるキーワードもあれば、見たことも聞いたこともないキーワードもあるかもしれません。
しかし、これらのキーワードを理解することが、機械学習を学ぶ上で不可欠なことです。
それぞれのキーワードについて、理解を深めるためには、個別の学習が必要になります。
ぜひ、本記事を参考にして、機械学習に関する知識を身につけてください。
機械学習でよく使われるキーワードと説明
以下は、機械学習でよく使われるキーワードに簡単な説明を加えた一覧表です。
| キーワード | 説明 |
|---|---|
| クラス分類 | データを事前に定義されたカテゴリー(クラス)に分類するタスク |
| 回帰 | データを事前に定義された値に予測するタスク |
| 教師あり学習 | 入力データと出力データのペア(教師データ)を利用して学習を行う方法 |
| 教師なし学習 | 教師データを利用せずに、データの構造や特徴を抽出する方法 |
| 強化学習 | マルチエージェントシステムにおいて、報酬を最大化するために行動を決定する方法 |
| 深層学習 | 複数の中間層を持つニューラルネットワークを利用して、高度な特徴抽出や分類を行う方法 |
| ニューラルネットワーク | ニューロンのネットワークを模倣した機械学習の手法 |
| バッチ学習 | 全てのデータを一度に使ってモデルを学習する方法 |
| オンライン学習 | データを一部ずつ使ってモデルを学習する方法 |
| ディープラーニング | 多層のニューラルネットワークを利用して、高度な特徴抽出や分類を行う方法 |
| ランダムフォレスト | 複数の決定木を組み合わせたアンサンブル学習法で、多数決により分類・予測を行う方法 |
| SVM | カーネル法を用いて、高次元空間での線形または非線形分類を行う方法 |
| PCA | データの次元削減を行う方法。データの特徴を維持しつつ、情報量を削減することができる |
| k-NN | 最近傍法を用いて、未知のデータに最も近いk個のデータのクラスを予測する方法 |
| モデル選択 | データに最適なモデルを選択する方法 |
| クラスタリング | データを自動的にクラスターに分類する方法 |
| 次元削減 | 多次元データの特徴量を削減し、データの次元を圧縮する手法 |
| 特徴選択 | モデルの学習に不要な特徴量を削除し、データの次元を削減する手法 |
| 正則化 | モデルの複雑さを制御し、過学習を抑制する手法 主にL1正則化・L2正則化が用いられる |
表に記載したキーワードは基本的な手法から応用的な手法まで、幅広くカバーしており、それぞれの手法を理解することで機械学習の基礎を固めることができます。
機械学習でよく使われる各キーワードの解説
以下に各キーワードの詳細解説を記載いたしますので、さらに理解を深め、機械学習を理解するための第一歩としてください。
クラス分類
クラス分類は、入力されたデータが事前に定義されたカテゴリー(クラス)に分類されるタスクです。
- 例えば
- 手書きの数字画像を「0」〜「9」の数字に分類

クラス分類は、主に教師あり学習で行われます。
手書き数字のデータセット:MNIST(エムニスト)については、用語集の解説をご覧ください。
回帰
回帰は、入力されたデータが事前に定義された値に予測されるタスクです。
- 例えば
- 不動産の価格を予測

回帰は、主に教師あり学習で行われます。
教師あり学習
教師あり学習は、入力データと出力データのペア(教師データ)を利用して学習を行う方法です。
- クラス分類
- 回帰

教師なし学習
教師なし学習は、教師データを利用せずに、データの構造や特徴を抽出する方法です。
- 主に
- クラスタリング
- 次元削減

強化学習
強化学習は、マルチエージェントシステムにおいて、報酬を最大化するために行動を決定する方法です。
- 主に
- ゲームの制御
- ロボットの制御

深層学習
深層学習は、複数の中間層を持つニューラルネットワークを利用して、高度な特徴抽出や分類を行う方法です。
- 主に
- 画像認識
- 自然言語処理

ニューラルネットワーク
ニューラルネットワークは、ニューロンのネットワークを模倣した機械学習の手法です。
- 入力層
- 中間層
- 出力層
- 各層の間の重みを調整することで学習を行う
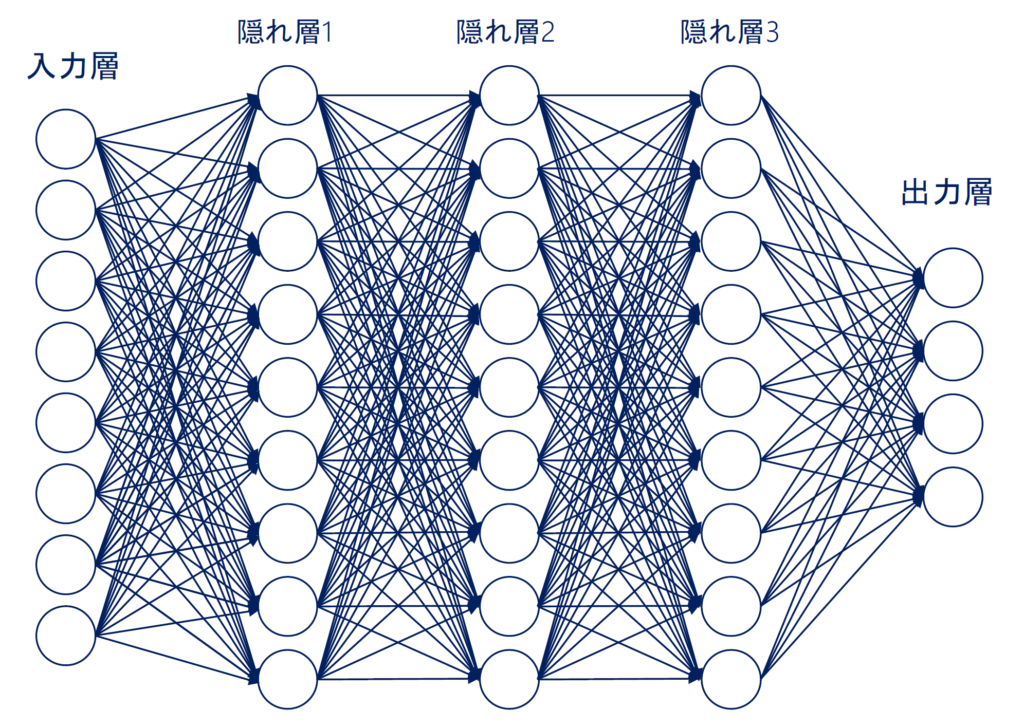
※中間層という表現は、「隠れ層(hidden layer)」以外の入出力層を含めた総称的な呼び方です。
バッチ学習とオンライン学習
- バッチ学習:
- 全てのデータを一度に使ってモデル学習
- 精度がいい
- 時間がかかる
- 全てのデータを一度に使ってモデル学習
- オンライン学習:
- データを一部ずつ使ってモデル学習
- 精度が不安定になる場合がある
- 速い
- データを一部ずつ使ってモデル学習
バッチ学習
バッチ学習は、全てのデータを一度に使ってモデルを学習する方法です。
- 全データを一度に用いるため、モデルが一度に更新される
- 大量のデータを扱う場合:
- メモリの問題が発生することがある
- 一度の学習に時間がかかるという欠点がある
- 大量のデータを扱う場合:
オンライン学習
オンライン学習は、データを一部ずつ使ってモデルを学習する方法です。
- 全データを一部ずつ使うため、モデルの更新がリアルタイムで行える
- 大量のデータを扱う場合:
- メモリの問題を回避可能
- データが常に更新されるような環境:
- リアルタイムで学習が行えるため、応用範囲が広いという利点がある
- 大量のデータを扱う場合:
ディープラーニング
ディープラーニングは、多層のニューラルネットワークを利用して、高度な特徴抽出や分類を行う方法です。
- ニューラルネットワークの層を深くする
- →より複雑な問題に対して高い精度で解決することが可能
- 3層以上にすることが推奨されている
- ただし、層が多すぎると、過学習に陥る
- 適切な層数を選ぶ必要がある
- →より複雑な問題に対して高い精度で解決することが可能

近年では、画像認識や自然言語処理などの分野で大きな成果があがっています。
ランダムフォレスト
ランダムフォレストは、複数の決定木を組み合わせたアンサンブル学習法で、多数決により分類・予測を行う方法です。
- 決定木:
- 一つの木構造でデータを分類するアルゴリズム
- ランダムフォレスト:
- 複数の決定木を組み合わせることで
- より正確な分類・予測を行うことができる
- 複数の決定木を組み合わせることで
SVM
SVM(Support Vector Machine)は、カーネル法(※1)を用いて、高次元空間での線形または非線形分類を行う方法です。
- SVM:
- 分類問題や回帰問題において高い性能を発揮する機械学習の手法の一つ
- 決定境界(※2)から最も近いデータ点(サポートベクトル)に注目することで、分類を行う
高い分類性能を持ち、さまざまな分野で活用されています。
※1. カーネル法:データを高次元空間に写像し、その空間での内積を計算することによって、元のデータの非線形な関係を捉える手法。
- 代表的なカーネル関数
- 線形カーネル
- 多項式カーネル
- ガウシアンカーネル
- などがある
※2. 決定境界:分類器がデータを2つまたはそれ以上のクラスに分類する際に、そのクラスを区切る境界線のこと。決定境界は、分類器がデータを正しく分類するために重要な役割を担っており、決定境界の形状によって分類器の性能が大きく変わることがあります。
- 例えば、2つのクラスを分類する問題を考えた場合:
- 決定境界は直線や曲線などで表現される
- 分類器がデータを正しく分類するためには
- 決定境界ができるだけ適切な位置にあることが必要
- 決定境界が複雑であるほど、過学習を起こす可能性がある
- 適切なモデルの選択やパラメータ調整が重要
- 分類器がデータを正しく分類するためには
- 決定境界は直線や曲線などで表現される
PCA
PCAは、Principal Component Analysis(主成分分析)の略で、データの次元削減を行う方法です。
- データの特徴を維持しつつ、情報量を削減することができる
- PCA:
- データの分散が最大になる方向(主成分)を見つけ出し
- その方向に射影したデータを新しい軸として用いる
- 元のデータよりも少ない次元数でデータを表現することが可能
- その方向に射影したデータを新しい軸として用いる
- データの分散が最大になる方向(主成分)を見つけ出し
主に、画像処理や音声認識などの分野で広く用いられています。
特徴選択
特徴選択は、モデルの学習に不要な特徴量を削除し、データの次元を削減する手法です。
- 特徴選択を行うことで
- モデルの過学習を防ぐことができる
- モデルの予測精度を高めることができる
主な手法には、フィルタ法、ラッパー法、埋め込み法などがあります。
正則化
正則化は、モデルの複雑さを制御し、過学習を抑制する手法です。
主にL1正則化・L2正則化が用いられます。
- L1正則化:
- 重みをできるだけ0に近づけるように制御
- モデルのスパース性(※)を高める
- 重みをできるだけ0に近づけるように制御
- L2正則化:
- 重みの大きさを制限する
- モデルの一般化性能を向上させる
- 重みの大きさを制限する
正則化は、機械学習において欠かせない手法の一つであり、適切に選択することでモデルの予測精度を向上させることができます。
※ スパース性:ベクトルや行列の要素のうち、0に近い値を持つ要素が非常に多い状態のことを指します(スパースでない状態は「密な状態」と呼ぶ)。
- スパース性:
- 0に近い値を持つ要素が非常に多い状態
- スパースでない状態:
- 「密な状態」と呼ぶ
機械学習において、スパース性は、特徴選択や次元削減などの手法において重要な役割を担います。
例えば、
- 疎な特徴行列に対して線形回帰を行った場合:
- スパース性を持つ行列:
- 多くの特徴量が0となる
- 余分な計算を省くことができる
- 多くの特徴量が0となる
- スパース性を持つ行列:
また、スパース性は、解釈性の向上や過学習の防止にも役立ちます。
一方、密な状態の場合は、計算量が非常に大きくなるため、計算上の課題が生じることがあります。
Pythonで実装する線形回帰モデル
機械学習のキーワードやアルゴリズムを理解するためには、サンプルコードを試して、実際にグラフが描画されることを確認するような立体的な学習が大切です!
ここでは、簡単なPythonコードを用いた機械学習のサンプルを紹介します。
サンプルコードを実行して、手軽に機械学習のアルゴリズムを試してみましょう。
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
# ボストン市の住宅価格データをロード
boston = load_boston()
# 説明変数と目的変数に分割
X = boston.data[:, 5].reshape(-1, 1)
y = boston.target
# 線形回帰モデルを作成
model = LinearRegression()
# モデルを学習
model.fit(X, y)
# グラフを作成
plt.scatter(X, y, color='blue')
plt.plot(X, model.predict(X), color='red', linewidth=2)
plt.title('Boston Housing Prices')
plt.xlabel('Number of rooms')
plt.ylabel('Price ($1000s)')
# グラフを表示
plt.show()このコードを Jupyter Notebook に貼り付けて実行すると、このようなグラフが描画されます。
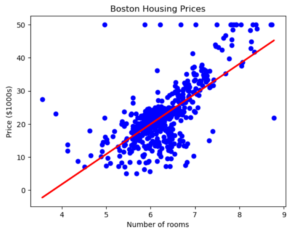
このコードは、ボストン市の住宅価格データを用いて、部屋数と住宅価格の関係を線形回帰モデルで学習し、その結果をグラフ化しています。
グラフを見ることで、部屋数が増えるにつれて住宅価格が上昇する傾向があることが視覚的に確認できます。
サンプルコードの解説
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_bostonmatplotlib、scikit-learn、およびボストン市の住宅価格データをインポートしています。
# ボストン市の住宅価格データをロード
boston = load_boston()load_boston()関数を用いて、ボストン市の住宅価格データを読み込み、bostonという変数に格納しています。
ここで、bostonは、データセットの辞書形式のオブジェクトで、データや特徴量、説明変数の情報を持っています。
# 説明変数と目的変数に分割
X = boston.data[:, 5].reshape(-1, 1)データセットから5番目の特徴量である「部屋数」を説明変数として、目的変数である「住宅価格」を取り出しています。
.reshape(-1, 1)は、1次元の配列を2次元の配列に変換しています。
これは、scikit-learnのモデルにデータを適用するために必要な形式に変換するためです。
y = boston.targetboston.targetから目的変数である「住宅価格」を取得しています。
# 線形回帰モデルを作成
model = LinearRegression()LinearRegression()クラスを用いて線形回帰モデルを作成し、modelという名前でインスタンス化しています。
# モデルを学習
model.fit(X, y)model.fit()メソッドを用いて、説明変数と目的変数を使ってモデルを学習しています。
# グラフを作成
plt.scatter(X, y, color='blue')
plt.plot(X, model.predict(X), color='red', linewidth=2)
plt.title('Boston Housing Prices')
plt.xlabel('Number of rooms')
plt.ylabel('Price ($1000s)')matplotlibを用いてグラフを作成しています。
plt.scatter()メソッドを用いて、散布図を描画し、plt.plot()メソッドを用いて、線形回帰モデルの予測結果を描画しています。
また、plt.title()、plt.xlabel()、plt.ylabel()メソッドを用いて、グラフのタイトルや軸ラベルを設定しています。
# グラフを表示
plt.show()plt.show()メソッドを用いて、グラフを表示しています。
次の項目では、機械学習を本格的に学んでいくために必要となる、代表的なオープンソースの機械学習ライブラリを紹介していきます。
オープンソース機械学習ライブラリ PyTorch と TensorFlow
オープンソース機械学習ライブラリの代表的な2つ、PyTorchとTensorFlowを紹介します。
PyTorchはPythonで開発されたライブラリで、GPUを利用した深層学習モデルの構築や学習、評価を高速かつ容易に行うことができます。
一方、TensorFlowはGoogleによって開発されたライブラリで、機械学習モデルの構築や学習、展開を行うためのフレームワークです。
両方とも、多くの機能を備えた強力なライブラリであり、機械学習の分野で広く使われています。
pytorch
Pythonで開発されたオープンソースの機械学習ライブラリ「PyTorch」のリポジトリ。
「PyTorch」は、Pythonで開発されたオープンソースの機械学習ライブラリです。
ディープラーニングのための高速なテンソル演算や、自動微分に対応し、ニューラルネットワークの構築や学習が簡単にできるようになっています。
また、転移学習や強化学習など、様々な機械学習のアプローチに対応しています。
GitHub上で公開されており、世界中の開発者たちが開発や改善に取り組んでいます。
tensorflow
「TensorFlow」は、Googleが開発した機械学習のためのオープンソースライブラリ。
本リポジトリは、TensorFlowのソースコードが公開されている場所です。
分散処理やモデルの自動微分、グラフ最適化などの機能を備え、データフローグラフによる記述が可能です。深層学習をはじめとした機械学習の実装に広く利用されています。
まとめ
AIには様々な技術がありますが、その中でも機械学習は最も基礎的な技術の1つです。
本記事では、機械学習に欠かせない19のキーワードを詳しく解説しました。
機械学習を理解するためには、これらのキーワードを把握することが必要不可欠です。
初心者の方にもわかりやすいように解説しているので、AIに興味がある方はぜひ本記事を参考にしてみてください。
この記事が、あなたのAI学習に踏み出す最初の一歩を踏み出すお手伝いになれたら幸いです。

見て試してわかる機械学習アルゴリズムの仕組み 機械学習図鑑

スッキリわかるPythonによる機械学習入門 スッキリわかるシリーズ


コメント